This work is licensed under a Creative Commons Attribution-ShareAlike 3.0 Unported License. This means that you are able to copy, share and modify the work, as long as the result is distributed under the same license.
Over-Representation Analysis (ORA) Practical Lab: GSEA
by Veronique Voisin
Introduction
This practical lab contains one exercise. It uses GSEA to perform a gene-set enrichment analysis.
Goal of the exercise
Learn how to run GSEA and explore the results.
Data
The data used in this exercise is gene expression (transcriptomics) obtained from high-throughput RNA sequencing. They correspond to Ovarian serous cystadenocarcinoma samples. This cohort was previously stratified into four distinct expression subtypes PMID:21720365 and a subset of the immunoreactive and mesenchymal subtypes are compared to demonstrate the GSEA workflow.
How was the data processed?
Gene expression from the TCGA Ovarian serous cystadenocarcinoma RNASeq V2 cohort was downloaded on 2015-05-22 from cBioPortal for Cancer Genomics. Differential expression for all genes between the mesenchymal and immunoreactive groups was estimated using edgeR.
Exercise
Our goal is to upload the 2 required files into GSEA, set up the parameters, run GSEA, open and explore the gene-set enrichment results. The 2 required files are a rank file (.rnk) and a pathway file (.gmt).
To generate a rank file (.rnk), a score (-log10 * pvalue * sign(logFC)) was calculated from the EdgeR differential expression results. It is used to rank the genes from top up-regulated to top down-regulated (all genes are included). The pathway database (.gmt) used for the GSEA analysis was downloaded from http://baderlab.org/GeneSets. This file contains gene-sets obtained from MsigDB-c2, NCI, Biocarta, IOB, Netpath, HumanCyc, Reactome and the Gene Ontology (GO) databases. More information on how EdgeR was performed is included at the bottom of the page in the Additional Information section .
GSEA performs a gene-set enrichment analysis using a modified Kolmogorov-Smirnov statistic. The output result folder contains several files, and two of them are the summary tables displaying enrichment statistics for each gene-set (pathway) that has been tested and contained in the provided .gmt file.
Before starting this exercise, download the 2 required files:
Additional information
More on processing the RNAseq using EdgeR and generate the .rank file
More on which .gmt file to download from the Baderlab gene-set file, select current release, Human, symbol, Human_GOBP_AllPathways_no_GO_iea_….gmt
More on GSEA : link to the Baderlab wiki page on GSEA
Start the exercise:
Step1.
Launch GSEA.

Step 2.
Load Data
2a. Locate the ‘Load data’ icon at the upper left corner of the window and click on it.
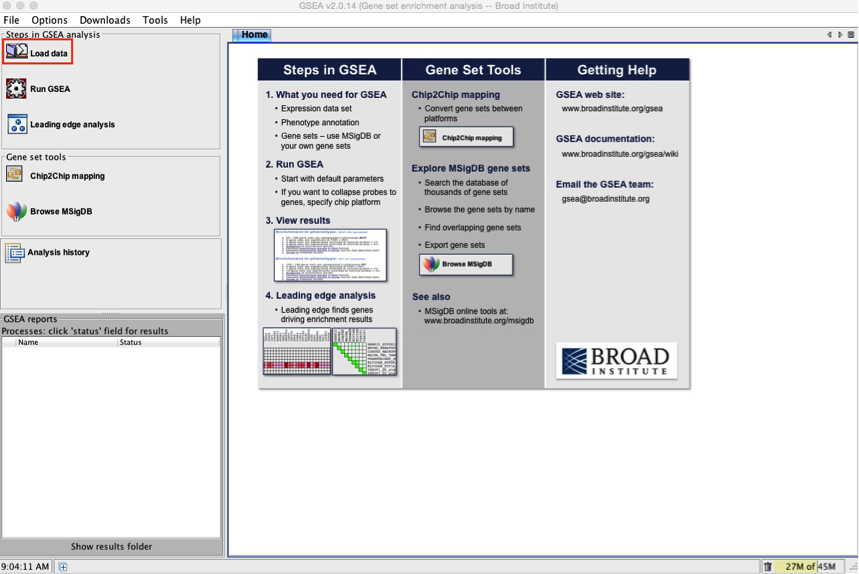
2b. In the central panel, select ‘Method 1’ and ‘Browse for files’. A new window pops up.
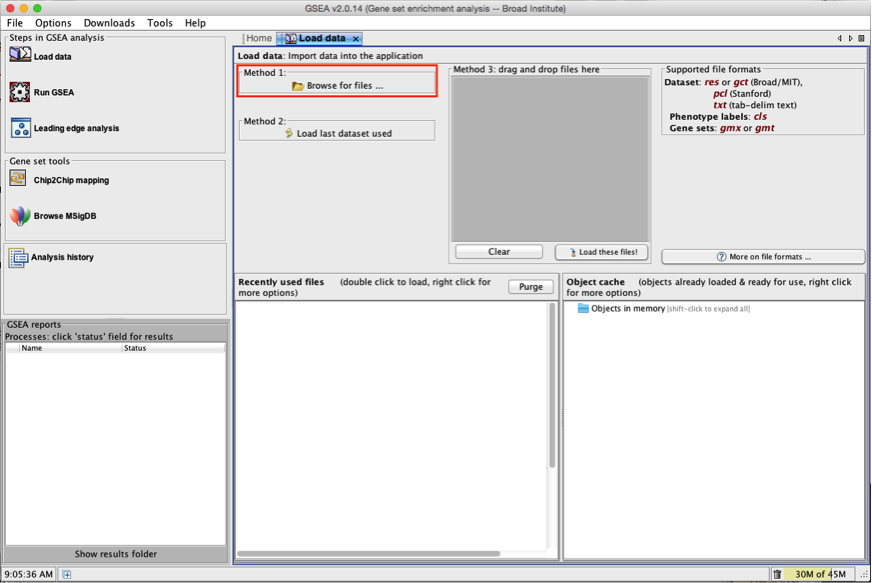
2c. Browse your computer to locate the 2 files : Human_GOBP_AllPathways_no_GO_iea_May_24_2016_symbol.gmt and MesenchymalvsImmunoreactive_edger_ranks.rnk.
2d. Click on Choose. A message pops us when the files are loaded successfully.
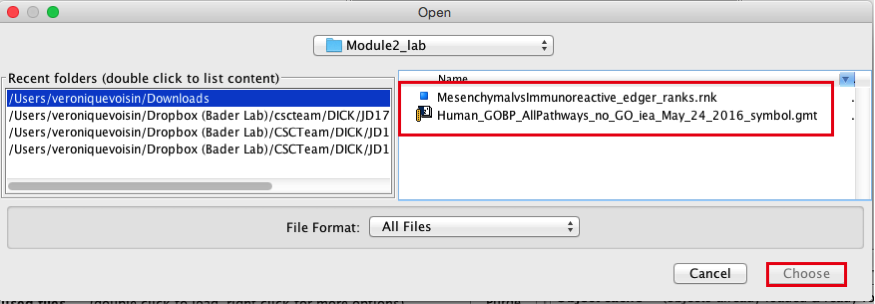
2e. Click on OK.

Tip: Alternatively, you can choose Method 3 to drag and drop files here; you need to click on the Load these files! button in this case.
Step3.
Adjust parameters
3a. Under the Tools menu select GseaPreRanked.
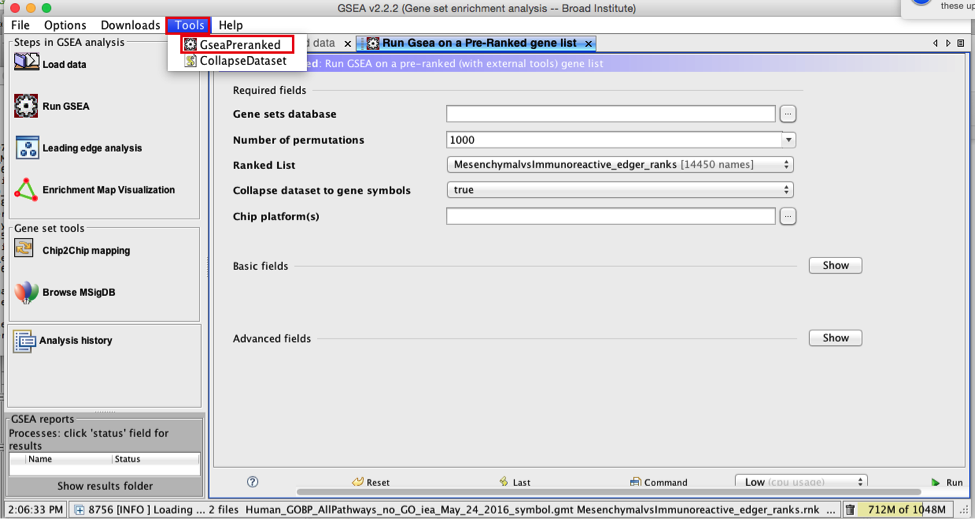
3b. Run GSEA on a Pre-Ranked gene list tab will appear.
Specify the following parameters:
3c. Gene sets database -
-
click on the radio button (…) located at the right of the blank field.
-
Wait 5-10sec for the gene-set selection window to appear.
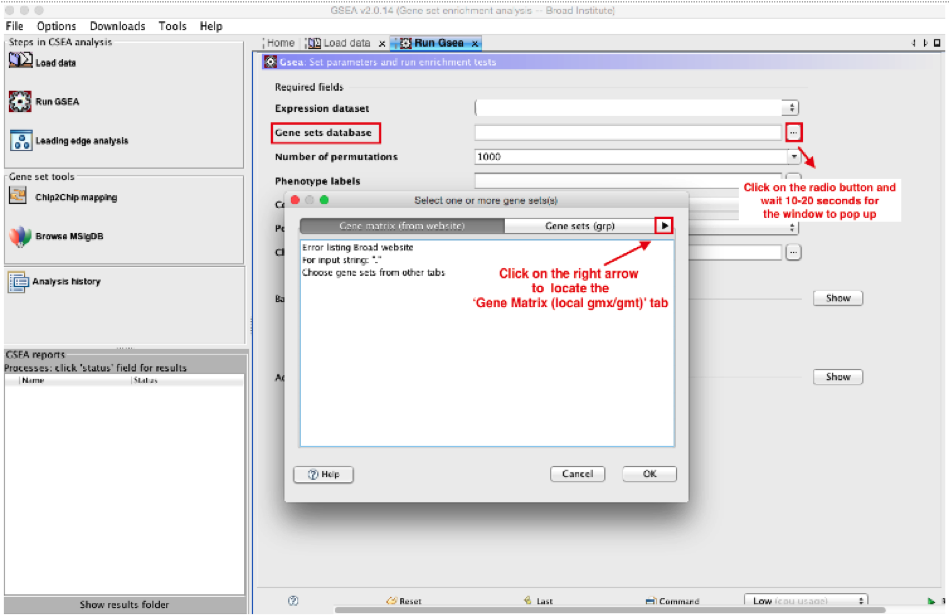
-
Use the right arrow in the top field to see the Gene matrix (local gmx/gmt) tab.
-
Click to highlight Human_GOBP_AllPathways_no_GO_iea_May_24_2016_symbol.gmt.
-
click on OK at the bottom of the window.
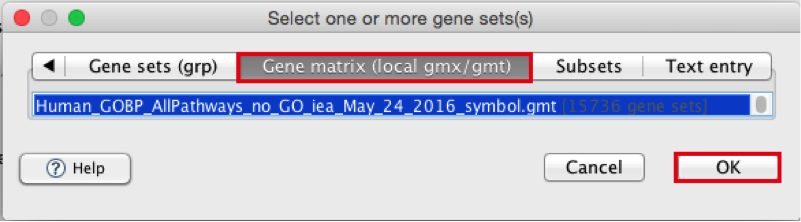
- Human_GOBP_AllPathways_no_GO_iea_December_24_2015_symbol.gmt is now visible in the field corresponding to Gene sets database.
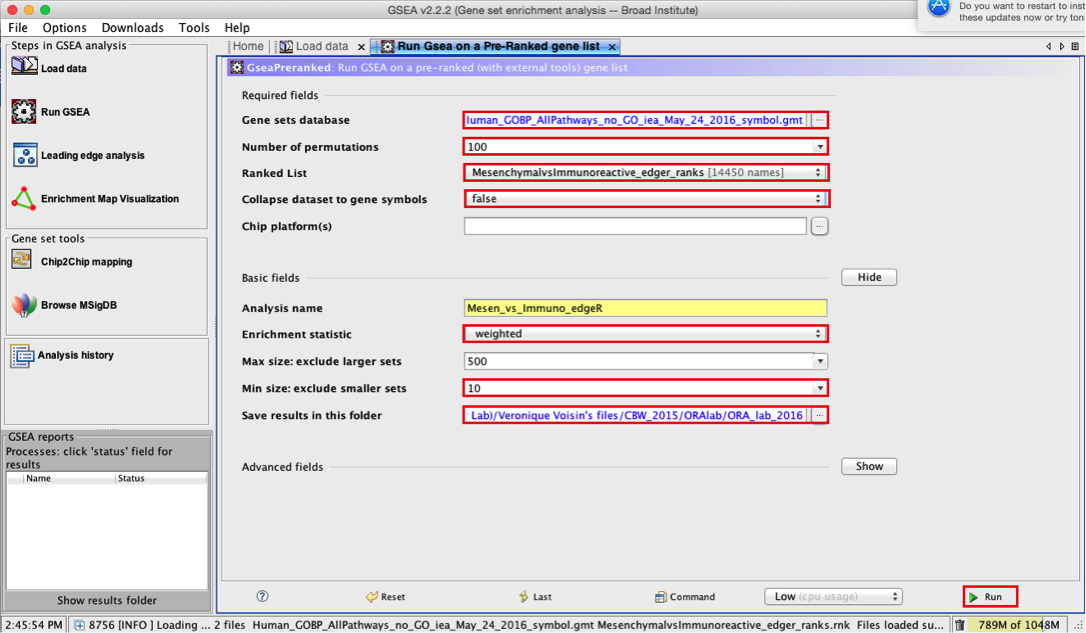
3d. Number of permutations - 100. The number of permutations is the number of times that the gene-sets will be randomized in order to create a null distribution to calculate the FDR.
3e. Ranked list - select by clicking on the arrow and highlighting rank file.
3f. Collapse dataset to gene symbols - set to false.
3g. Chip platform(s) - should be left empty. Click on Show button next to Basic Fields to display extra options.
3h. Analysis name – change default my_analysis to name specific to analysis for example Mesen_vs_Immuno_edgeR. GSEA will use your specified name as part of the name of the results directory it creates.
3i. Save results in this folder – navigate to where you want GSEA to put the results folder. By default GSEA will put the results into the directory gsea_home/output/[date] in your home directory.
3j. Min size: exclude smaller sets – By default GSEA sets the lower limit to 15. In this protocol, the minimum is set to 10 to increase some of the smaller sets in the results.
Note: Number of permutations is set to 100 to reduce the run time during this exercise. When you analyze your data, set Number of permutations to 1000.
Tip: set Enrichment Statistics to p1 if you want to add more weight on the most top up-regulated and top down-regulated. P1 is a more stringent parameter and it will result in less gene-sets significant under FDR <0.05.
Step 4.
Run GSEA
4a. Click on Run button located at the bottom right corner of the window.
TIP: Expand the window size if the run button is not visible
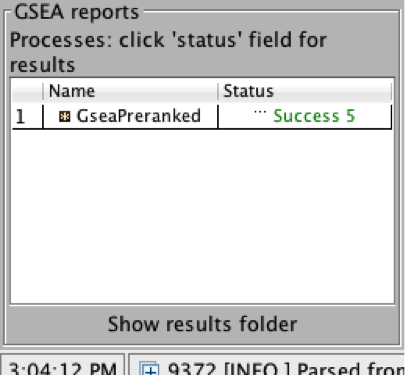
4b. On the panel located on the left side of the GSEA window, the bottom panel called the GSEA report table will show that it has created a process with a message that it is Running.
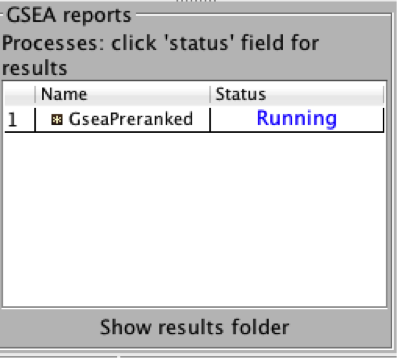
On completion the status message will be updated to Success….
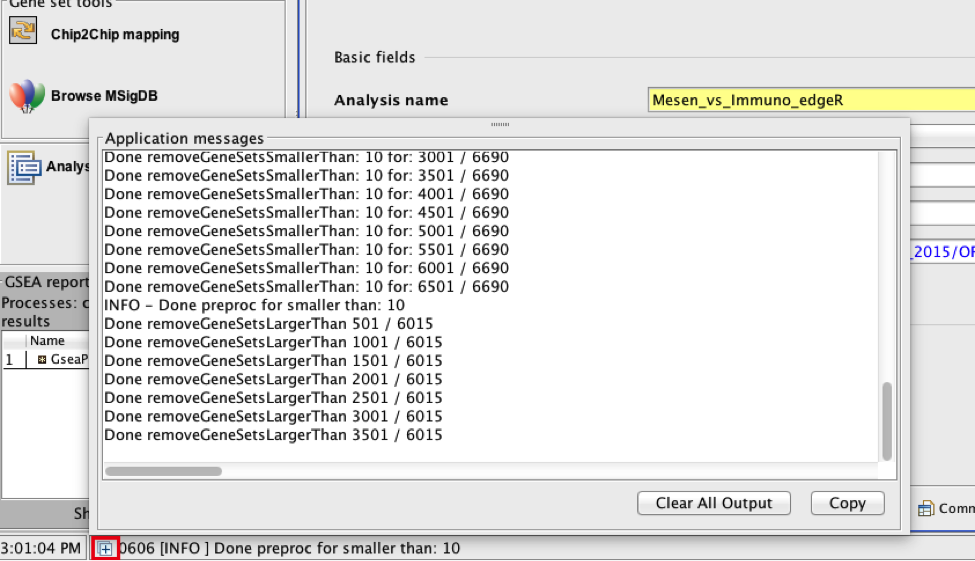
TIP: There is no progress bar to indicate to the user how much time is left to complete the process. Depending on the size of your dataset and compute power a GSEA run can take from a few minutes to a few hours. To check on the status of the GSEA run in the bottom left hand corner you can click on the + (red circle in below Figure) to see the updating status. Printouts in the format shuffleGeneSet for GeneSet 5816/5821 nperm: 1000 indicate how many permutations have been done (5816) out of the total that need to be performed (5821).
TIP:if the permutations have been completed but the status is still running, it means that GSEA is creating the report
TROUBLESHOOTING: Java Heap Space error. If GSEA returns an error Java Heap space it means that GSEA has run out of memory. If you are running GSEA from the webstart other than the 4GB option then you will need to download a new version that allows for more memory allocation. The current maximum memory allocation that the GSEA webstart allows for is 4GB. If you are using this version and still receive the java heap error you will need to download the GSEA java jar file and launch it from the command line as described in step 1.
Step 5.
Examining the results
5a. Click on Success to launch the results in html format in your default web browser.
TIP: If the GSEA application has been closed, you can still see the results by opening the result folder and clicking on the index file – index.html.
When examining the results there are a few things to look for:
5b. Check the number of gene-sets that have been used for the analysis.
TIP: A small number (a few hundred genesets if using baderlab genesets) could indicate an issue with identifier mapping.
5c. Check the number of sets that have FDR less than 0.25 – in order to determine what thresholds to start with when creating the enrichment map. It is not uncommon to see a thousand gene sets pass the threshold of FDR less than 0.25. FDR less than 0.25 is a very lax threshold and for robust data we can set thresholds of FDR less than 0.05 or lower.
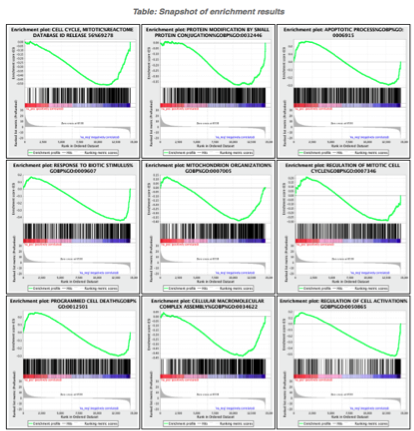
5d. Click on Snapshots to see the trend for the top 20 genesets. For the positive phenotype the top genesets should show a distribution skewed to the left (positive) i.e. genesets have predominance of up-regulated genes. For the negative phenotype the top geneset should be inverted and skewed to the right (negative) i.e. geneset have predominance of down-regulated genes.
5e. Explore the tabular format of the results.


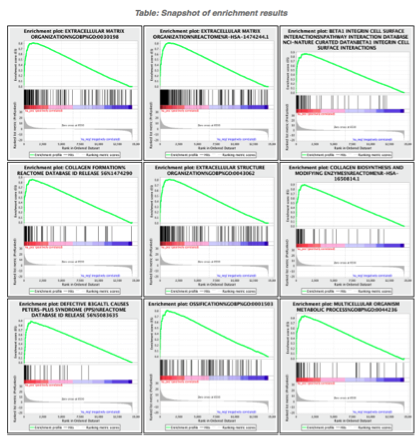
Mesenchymal
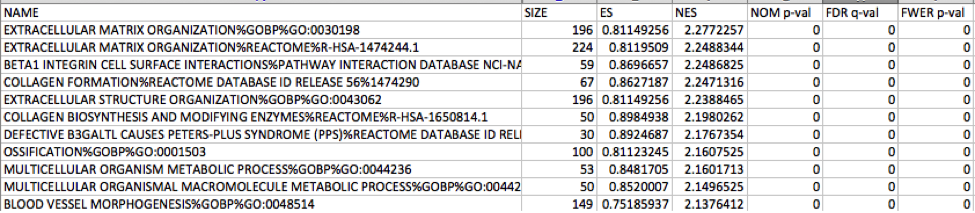
Immunoreactive
